
Crawl budget, apa itu? Apakah maksudnya adalah biaya perayapan yang akan kita bayarkan kepada mesin pencari seperti Google?
Tapi sayangnya bukan itu maksud dari crawl budget.
Agar teman-teman yang baru mempelajari SEO tidak salah kaprah, yuk mari kita ulas apa itu crawl budget dan pentingkah ia untuk SEO Campaign kita.
Daftar Isi
Apa itu crawl budget?
Menurut Google, crawl budget adalah suatu anggaran perayapan jumlah URL yang dapat dan ingin dirayapi Googlebot.
Lebih detilnya lagi, crawl budget adalah jumlah halaman yang dirayapi dan diindeks oleh Googlebot pada sebuah situs web dalam rentang waktu tertentu.
Jadi contoh sederhananya (tanpa memperhatikan sisi teknis lengkapnya), apabila teman-teman memiliki atau mengelola situs web dengan jumlah 100 halaman, maka itulah jumlah total halaman yang akan dirayapi (crawl) dan diindeks oleh Google.
Crawl budget ini merupakan formula dari dua hal, yaitu:
- Crawl rate limit: jumlah maksimum pengaksesan data dari suatu situs web, agar situs tersebut tidak lemot karena terlalu banyak pengunjung
- Crawl demand: permintaan jumlah indexing, yang dipengaruhi oleh popularitas situs (semakin populer sebuah situs akan semakin sering di-crawl situs itu)
Pentingkah crawl budget di SEO?
Begini, SEO itu kan tentang proses untuk membuat sebuah situs web terindeks dan mendapatkan peringkat halaman terbaik (page one) di SERP (Search Engine Results Page).
Perlu teman-teman ketahui, bahwa cara kerja mesin pencari itu terjadi atas 3 tahap, yaitu:
- Crawling
- Indexing
- Serving atau Ranking
Bisa kita lihat pada daftar di atas, langkah pertama yang dikerjakan mesin pencari dengan bot-nya adalah crawling (perayapan).
Sehingga jika tidak ada proses crawling, maka tidak akan ada yang namanya indexing, dan akhirnya situs web teman-teman tidak mendapatkan serving atau ranking di mesin pencari.
Tidak tampil di mesin pencari seperti Google artinya situs web tidak akan mendapatkan traffic yang merupakan salah satu indikator kesuksesan SEO Campaign teman-teman.
Kesimpulannya, apakah crawl budget itu penting? Ya, sangat penting!
Namun teman-teman jangan terlalu cemas, karena Google sendiri menyampaikan bahwa, crawl budget bukanlah hal yang harus teman-teman fokuskan, kecuali situs yang dikelola adalah:
- Situs berskala besar (lebih dari 1 juta halaman unik) dengan konten yang cukup sering berubah (satu minggu sekali)
- Situs berskala menengah (lebih dari 10 ribu halaman unik) dengan konten yang berubah setiap harinya
- Terlalu banyak mendapatkan status Discovered – currently not indexed
Faktor-faktor yang mempengaruhi crawl budget
Supaya proses Crawl Budget ini efisien, maka teman-teman harus perhatikan faktor-faktor berikut, seperti dikutip dari panduan Google: Panduan pemilik situs besar untuk mengelola crawl budget (Large site owner’s guide to managing your crawl budget).
- Faceted navigation dan session identifiers
- Konten berkualitas rendah dan spam
- Konten duplikat atau ganda
- Status soft error pages (404, dst)
- Situs kena hack
- Infinity spaces
Selanjutnya, kita akan coba sedikit mengulas dari poin faktor-faktor yang mempengaruhi crawl budget di atas.
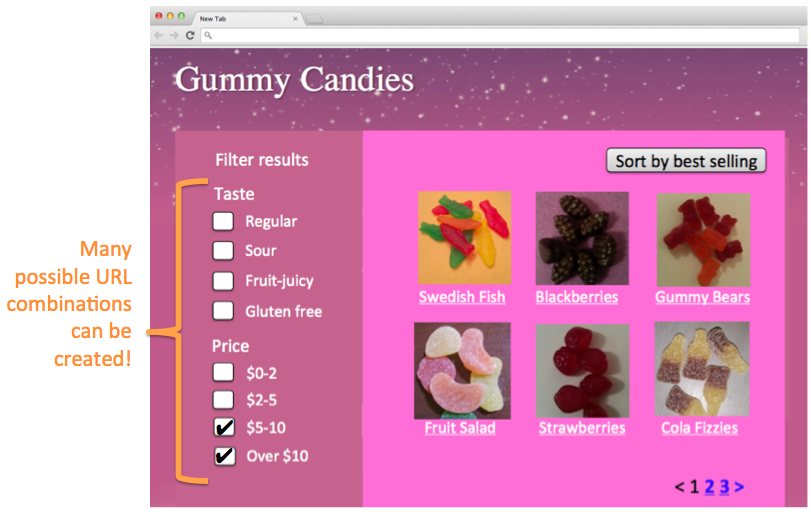
Pernah melihat tampilan menu seperti pada gambar di atas? Pasti teman-teman pernah ya berbelanja online?
Jika kita membuka situs E-Commerce semisal Tokopedia, Bukalapak, dan yang lainnya, biasanya kita akan disajikan menu navigasi opsi di sebelah kiri.
Pada menu tersebut terdapat beberapa filter atau opsi yang bisa kita pilih, dan itulah yang namanya faceted navigation.
Faceted navigation sendiri sebenarnya sangat bagus untuk pengalaman pengguna, tapi sayangnya sering kurang bersahabat dengan bot crawler.
Kenapa? Karena faceted navigation ini bisa menghasilkan kombinasi URL dan duplikat konten yang cukup banyak.
Dan kombinasi URL serta duplikat konten yang banyak ini pastinya akan membuat crawl budget menjadi boros dan tidak efisien.
Session identifiers
Praktik terbaik dalam SEO yang sudah kita tahu, adalah buat satu URL yang isi kontennya unik dan berkualitas, buang jauh-jauh konten duplikat. Tapi, session identifiers ini mempengaruhi crawl budget karena ia menciptakan banyak URL yang mengarah ke konten yang sama.
Sebagai contoh, anggaplah kita punya halaman tentang “sepatu adidas” dan URL-nya “www.sepatu.com/adidas”. Nah si session identifiers ini menambahkan paramater ke dalam URL tersebut tergantung user yang berkunjung menjadi:
- “www.sepatu.com/adidas?id=1A”
- “www.sepatu.com/adidas?id=2B”
- “www.sepatu.com/adidas?id=3C”
- “www.sepatu.com/adidas?id=4D”, dst
Seperti kita lihat, semua URL di atas menampilkan konten produk yang sama alias konten duplikat! Sehingga crawl budget pun akhirnya menjadi bertele-tele dan tidak ada value bagi bot crawler.
Konten duplikat
Seperti yang sudah dijelaskan di atas, konten duplikat atau konten ganda di dalam satu situs web merupakan hal yang harus dihindari. Baik dari isi keseluruhan konten, hingga intent-nya. Dan teman-teman pasti sepakat dengan saya ya?
Google sendiri yang menyarankan kita untuk memperhatikan hal ini, sehingga jika kita abaikan, maka akan memberikan beberapa dampak negatif seperti:
- Terlewatnya halaman penting untuk di-crawl
- Menurunkan kepopuleran URL
- Hingga menampilkan halaman yang tidak diinginkan di SERP, dst
Jadi jangan menyepelekan hal ini ya!
Konten berkualitas rendah dan spammy
Umumnya praktisi SEO menyebutkan bahwa low quality content (konten berkualitas rendah) adalah konten yang memiliki sedikit teks di dalam tag body.
Tapi tidak selamanya begitu, karena ada beberapa topik yang isi teksnya harus sedikit atau tidak terlampau panjang.
Dan panjang teks ini tergantung dari intent pengunjung dan jenis query-nya. Berikut adalah jenis-jenis query yang ada:
- Navigational query
- Transactional query
- Commercial query
- Dan, informational query
Jenis query ini juga biasa disebut dengan type of keyword atau keyword intent.
Jadi, isi teks yang panjang tidak selamanya konten berkualitas, tapi bagaimana isi konten itu menjawab apa yang dicari, dimaksud, dan ditanyakan oleh pengunjung situs web kita.
Sebagai contoh supaya teman-teman dapat gambarannya.
Andai kata ada pengunjung yang mencari query “cara daftar facebook”, yang teman-teman harus tuliskan adalah langkah-langkah cara daftarnya.
Seperti:
- Buka facebook.com
- Masukkan nama, email, dst
- Klik daftar
- Konfirmasi email atau nomor telepon
- Selesai!
Bukan mengisi konten yang panjang dan tak jelas seperti menjelaskan apa itu facebook? sejarah facebook, kelebihan kekurangan facebook, dan baru membahas langkah-langkah cara mendaftar facebook.
Hal ini tidak memiliki value bagi pengguna yang ingin tahu cara daftarnya, hanya membuang-buang waktu dan bertele-tele.
Status soft error pages
Soft error pages yang dimaksud di sini adalah soft 404, merupakan hal yang terjadi saat server web merespons dengan kode respons HTTP 200 OK untuk halaman yang tidak ada.
Karena soft error pages ini bisa membatasi cakupan crawling mesin pencari di situs web teman-teman.
Lebih baik menggunakan kode 404 not found supaya mesin pencari tahu jika URL ini tidak ada dan akan melewatinya (tidak dirayapi).
Ingat, situs web itu tidak terbatas karena link yang saling terhubung, namun waktu yang dimiliki bot crawler terbatas.
Jadi perbaikilah status soft error pages (404) ini secara menyeluruh.
Situs yang kena hack
Jika situs yang kita kelola saja bisa mengalami banyak kendala yang menyebabkan crawl budget sia-sia, apalagi situs web yang kena hack (retas).
Pasti situs kita akan menjadi lebih “rusak” dan semakin tidak sesuai dengan pedoman Google dan mesin pencari lainnya.
Situs yang kena hack artinya bahwa ada seseorang atau kumpulan orang yang bisa mengakses file situs web tanpa ada izin dari pemilik dan mengubah isi file tersebut.
Saran saya, tingkatkan keamanan situs teman-teman agar tidak mudah di-hack, lakukanlah backup mingguan, dan perbaiki situs yang kena hack secara cepat, tepat, dan menyeluruh.
Infinity Spaces
Definisi infinity spaces (ruang tak terbatas) adalah jumlah link yang sangat besar namun tidak dan/atau sedikit memiliki konten baru di dalamnya untuk diindeks googlebot.
Jika hal ini terjadi pada situs teman-teman, maka proses perayapan URL ini akan memakan bandwith yang tidak perlu, dan membuat googlebot gagal mengindeks konten yang penting di situs kita.
Dan hasilnya, proses perayapan ini sama sekali tidak efisien dan efektif.
Cara terbaik untuk membuat crawl budget efisien
1. Memantau status crawling situs
Seperti yang sudah dikatakan sebelumnya, jika situsnya:
Berskala besar, mempublikasi banyak konten rutin, dan terdapat pengalihan, maka teman-teman bisa melakukan pemantauan status crawling ini.
Caranya dengan menggunakan free tool Google yaitu Google Search Console (GSC).
Langkahnya, silahkan login ke GSC teman-teman, kemudian pilih settings, lalu pilih crawl stats.
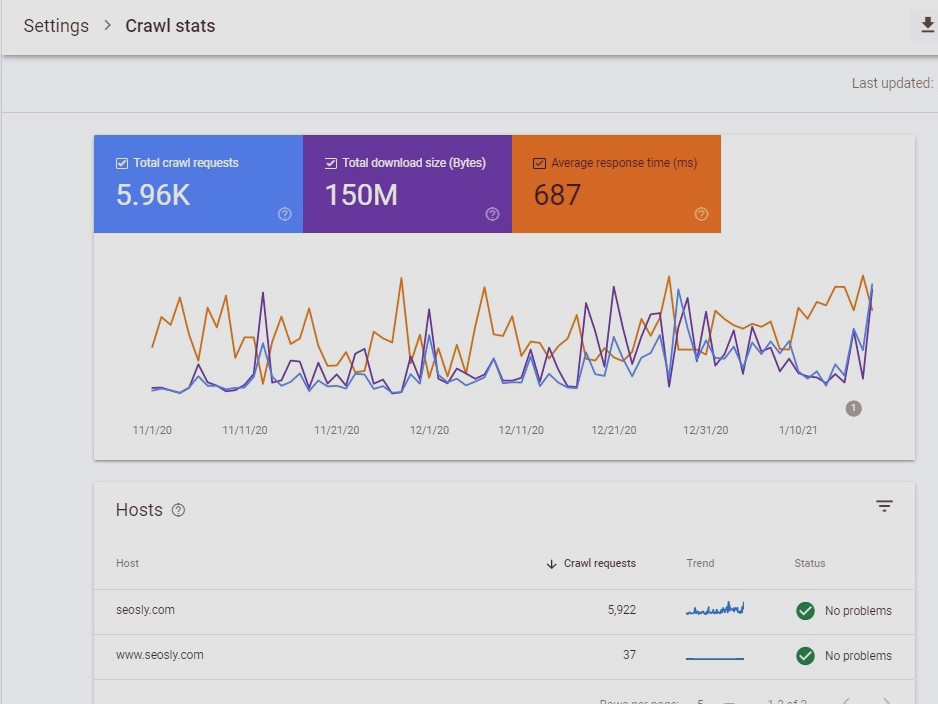
Di sana teman-teman bisa melihat laporan yang tersedia seperti: total crawl requests, total download size, hingga average response time.
Pastikan tidak laporan error di dalamnya, jika ada, maka teman-teman bisa bicarakan hal tersebut kepada tim developer situs webnya.
2. Meningkatkan kecepatan situs
Pemuatan situs web yang cepat dapat meningkatkan jumlah URL yang akan dirayapi oleh googlebot.
Making a site faster improves the users’ experience while also increasing crawl rate.
Google Developers
Jadi usahakan situs web dapat dimuat dengan cepat ya!
3. Menghapus konten duplikat
Prioritaskan pada halaman penting saja yang ingin diindeks, contohnya halaman produk, pilar konten, dst. Kemudian hapus konten yang duplikat atau tidak memiliki value sama sekali bagi pengunjung situs web. Dan pastikan hanya mempublikasi konten yang 100% berkualitas dan benar-benar unik.
4. Blokir crawling URL yang tidak ingin diindeks
Mungkin ada beberapa halaman yang memiliki nilai bagi pengunjung situs web, namun teman-teman tidak ingin mesin pencari mengindeksnya dan menampilkannya di hasil pencarian. Oleh karena itu tindakan pemblokiran URL ini perlu dilakukan.
Cara yang bisa teman-teman coba antara lain dengan memblok halaman ini dengan robots.txt. Contoh teks pemblokiran robots.txt:
User-agent: * Disallow: /wp-admin/ Disallow: /thankyou-page/
5. Perbarui Sitemap.xml Berkala
Pastikan untuk memperbarui file sitemap.xml secara berkala setiap ada konten yang baru ditulis atau baru di-update.
Kenapa? Karena Google membaca sitemap tersebut secara rutin.
Jangan lupa untuk memasukan url yang ingin diindeks ke dalam file sitemap, dan hindari memasukan url yang tidak ingin teman-teman indeks.
6. Hapus Kode Status Error
Menghapus halaman dengan kode status error seperti 404. Karena hal itu bisa membuang-buang waktu bot crawler dan membuat proses crawling tidak efisien alias boros.
7. Menghindari Redirect Chains
Redirect chain atau pengalihan berantai merupakan skema yang membuang-buang waktu googlebot dan sumber daya server. Sebagai contoh:
Ketika mengunjungi url abc.com/artikel, kemudian googlebot atau pengunjung dialihkan ke www.abc.com/artikel, kemudian dialihkan lagi ke https://www.abc.com/artikel/.
Apakah hal di atas efisien? Tentu tidak ya. Jadi perhatikan dan perbaiki long redirect chains ini agar crawl budget teman-teman menjadi lebih baik.
Penutup
Sekali lagi, teman-teman jangan khawatir tentang crawl budget ini selama situs web yang dikelola belum/tidak terlalu besar.
Namun tidak ada ruginya jika kita mempelajari crawl budget di awal, karena kita tidak pernah tahu, mungkin di hari esok situs web teman-teman akan menjadi the new big thing di internet!




5 Comments
Pingback: Mengenal Error 404 dan Soft 404, Apa Sih Perbedaan & Dampaknya? - DailySEO ID
Pingback: Apakah Website Terdaftar di Google Search Console Akan Di-Crawl Google Lebih Sering? - DailySEO ID
Pingback: Cara Kerja Google Search Engine: Crawling - Indexing - Ranking - DailySEO ID
Ijin bertanya terkait yang sitemap
Maksudnya rutin memperbaharui sitempa itu kita ngisi di gsc yang sitepa.xml berkali2 ya?
Bukan cuma sekali aja pas membuat web pertama?
Terima kasih
Memperbarui sitemap ini maksudnya ketika kita punya halaman yang ingin diindex, sebaiknya halaman/URL-nya dimasukkan ke sitemap. Nah, itu maksudnya memperbarui file sitemap.
Kalau pakai WordPress dan sudah install plugin seperti Yoast, biasanya ini otomatis.
Kalau memasukkan sitemap file ke GSC, ini cukup sekali saja.