")
Tepat di tanggal 25 Juli 2024, kami mendatangi event Google Search Central Live Jakarta 2024 (selanjutnya disingkat GSCL atau SCL) yang bertempat di Thamrin Nine Ballroom, Jakarta.
Acara tersebut dihadiri oleh pembicara dari Google seperti Gary Illyes, Cherry Prommawin, Collin Dion, William Prabowo, dan Alfin Ho.
Berbagai macam materi pun dibawakan dengan detail, mulai dari “Yang Baru di Penelusuran Google”, “Cara Kerja Penelusuran Google”, hingga “Tips Situs Belanja atau E-Commerce”.
Salah satu hal yang terbaru dan menarik untuk dibicarakan dalam artikel ini yaitu “Cara Kerja Penelusuran Google”, meskipun materi ini pernah disampaikan pada acara SCL 2023, namun Cherry sebagai narasumber menyampaikannya dalam versi yang “lebih panjang”.
Kenapa bisa begitu? Padahal, kalau ditelaah lebih lanjut cara kerja penelusuran Google hanya crawling, indexing, dan ranking saja.
Lantas, apa hal barunya? Untuk menjawab rasa penasaran tersebut, mari kita simak artikelnya sampai selesai!
Daftar Isi
Jumlah URL yang Tersebar di Internet
Sebelum membahas mengenai cara kerja Google, Cherry memberikan introduction yang menarik dengan menyebutkan jumlah URL yang ada di internet.
Teman-teman ada yang bisa menebak?
Ya, menurut pemaparan dari Cherry, setidaknya ada triliunan URL! Dengan banyaknya jumlah URL, lalu bagaimana Google dapat menemukan website kita?
Cara Kerja Penelusuran Google
Balik lagi ke pernyataan awal, cara kerja yang teman-teman ketahui saat ini mungkin crawling, indexing, dan ranking saja.
Namun, kenyataannya menurut penjelasan dari Cherry di acara Search Central Live Jakarta 2024, ada istilah baru yang muncul dari cara kerja penelusuran Google, yaitu:
Crawling > Indexing > Serving
Mari kita bahas satu per satu!
1. Crawling

Langkah utama Google dalam menemukan URL website kita yaitu dengan crawling.
Sebagian besar dari teman-teman mungkin sudah mengetahui bagaimana Google meng-crawl konten-konten kita.
Terlepas dari semua itu, Cherry menambahkan poin penting yang cukup membantu kita untuk mengetahui seberapa cepat Google dapat crawl website kita.
Setidaknya, kecepatan crawl yang dilakukan oleh Googlebot itu berbeda-beda untuk setiap website, tergantung dengan beberapa faktor, seperti:
- Seberapa cepat website bereaksi terhadap permintaan signal dari Googlebot
- Kualitas konten-konten website secara umum
- Ada beberapa potensi lain seperti server error
- Signal-signal lain
Setelah itu, Cherry juga menjelaskan beberapa poin penting yang patut kita pahami dengan saksama.
Pertama, “bagaimana kalau kita ingin minta ke Google untuk crawl website kita jarang-jarang?”
Untuk menjawab pertanyaan tersebut, Cherry mengatakan bahwa kita bisa menempatkan 502 atau 429 http status code ke Google supaya Googlebot tidak sering meng-crawl website Anda.
Kedua, “bagaimana kalau kita ingin Google meng-crawl terus-terusan ke website kita?”
Jawabannya adalah kita perlu meningkatkan kualitas website kita, baik itu dari segi page speed, kualitas konten, ataupun aspek SEO lainnya.
Tunjukkan kepada Google bahwa website kita mempunyai manfaat yang begitu besar buat user.
Lalu, hal yang tidak kalah penting yaitu Anda perlu menguatkan ekosistem website dengan membangun internal link yang solid.
Jadi, setiap ada konten baru yang teman-teman publish, setidaknya ada benang yang bisa menyambungkan ke konten lainnya, tidak menjadi konten tunggal semata.
Namun, perlu menjadi catatan teman-teman juga bahwa tidak ada jaminan konten kita akan mendapatkan ranking teratas jika Google lebih sering meng-crawl website kita.
Ketiga, “bagaimana jika kita ingin beberapa halaman website kita tidak di-crawl oleh Googlebot?”
Ya, teman-teman tentu sudah tahu jawabannya, yaitu dengan menggunakan robots.txt. Robots.txt berfungsi untuk menyembunyikan beberapa halaman kita supaya tidak dilihat oleh Google sehingga tidak muncul di SERPs (Search Engine Result Pages).

Setelah di-crawl dengan baik, Google akan melakukan fetch & render HTML, CSS ataupun JavaScript.
2. Indexing
Setelah Googlebot crawl website kita, langkah selanjutnya yaitu indexing. Google mempunyai database yang begitu besar untuk menampung semua website yang sudah di-crawl.
Pada tahapan ini, sebelum Google memasukkan halaman website ke tahap indexing, Google melakukan parsing HTML atau menguraikannya terlebih dahulu.
Sebagai contoh, di bawah ini ada sebuah HTML title:
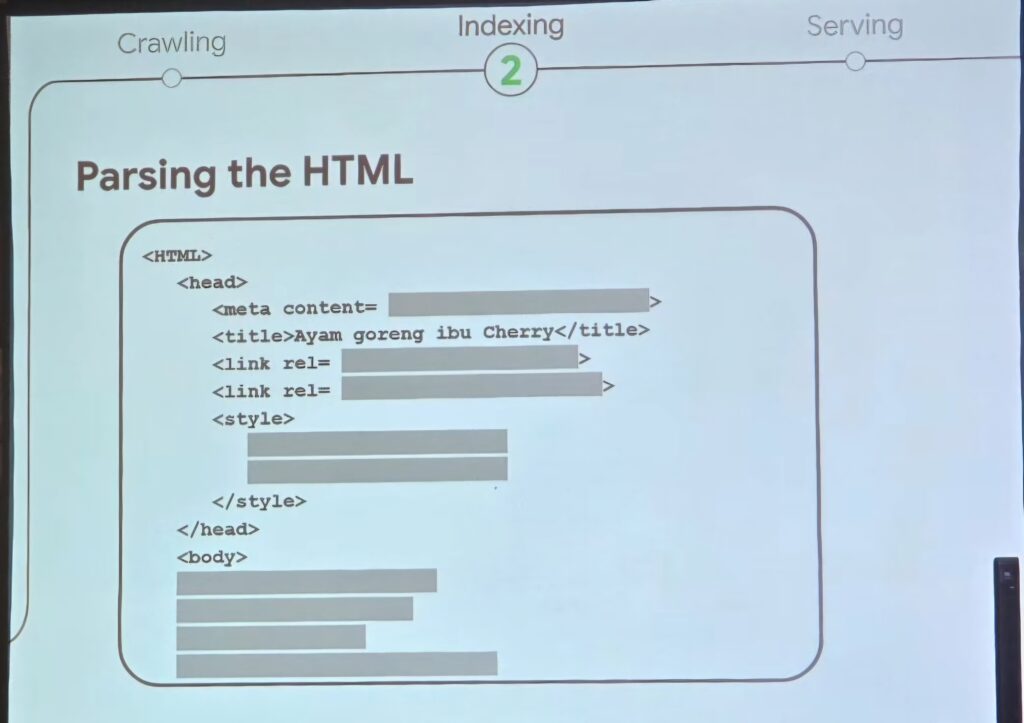
Dari situ, Google akan membaca HTML-nya terlebih dulu sebelum kemudian memasukkannya ke dalam indexing.
Setelah membaca HTML, Google akan coba memahami isi halaman dari website kita.
Untuk memudahkan Google dalam membaca konten kita, kita perlu memasukkan teks di dalamnya, tetapi teksnya harus bisa dibaca dan dipahami oleh user dengan baik.
Hal ini tentu saja diiringi dengan pembuatan konten yang helpful serta mengisi bagian-bagian penting seperti title, meta description, ataupun alt text image.
Kini, Google sudah paham dan baca semua halaman website Anda. Jika sudah demikian, Google akan melakukan pengecekan dan mengumpulkan mana saja halaman-halaman yang duplikat.

Dari situ, Google akan menentukan mana konten yang menjadi canonical alias jadi perwakilan dari tiap grupnya.
Tentu saja, kita tidak ingin membuat halaman di dalam website kita saling bersaing karena terindeks duplikat dengan Google.
Untuk mengatasi hal tersebut, kita perlu menyematkan rel=canonical ke satu halaman yang menurut teman-teman pantas mewakili dari semua halaman yang serupa. Pastikan halaman tersebut berkualitas, ya.
Jadi, secara umum Google hanya akan memilih mana konten yang berkualitas dan pantas untuk berada di SERP supaya mampu menjawab pertanyaan dari user.
3. Serving
Nah, ini merupakan tahap akhir dari Google sebelum nantinya konten kita akan ditampilkan di SERP.
Dalam tahapan ini, Google mencoba untuk memahami query/keyword yang akan dimasukkan di Google dan tentunya yang relevan dengan search intent user.
Pada tahapan ini Google akan membersihkan stop words atau kata yang sebenarnya tidak perlu dimasukkan Google sudah mengerti apa maksudnya. Contohnya seperti di bawah ini:

Dengan begitu, teman-teman bisa memaksimalkan kalimat dengan baik.
Setelah memahami query/keyword, Google akan menempatkan halaman yang paling relevan dengan keyword itu.
Perlu diingat, tidak semua halaman langsung ditampilkan di SERP, tetapi harus di-ranking dulu oleh Google.
Setidaknya, ada beberapa ranking signal yang perlu diketahui oleh teman-teman dari Google:
- Halaman web: teks di halaman, link ke halaman (internal link), bacaan, dsb
- Gambar: resolusi, warna, teks terkait, dsb
- Berita: aktualitas, keaslian, keunikan, dsb
- Lokal: lokasi, tipe, rating, ulasan, jam, dsb
- Video: bahasa, teks dari ucapan, dsb
Demikian penjelasan singkat mengenai cara kerja penelusuran Google yang disampaikan oleh Cherry Prommawin.
Bagi teman-teman yang perlu diskusi lanjutan mengenai pembahasan di atas, Anda bisa langsung bergabung ke dalam grup Telegram DailySEOID.
Ada banyak sekali praktisi SEO yang bisa diajak diskusi terkait hal tersebut. Selain itu, apabila teman-teman ingin belajar SEO dari fundamental hingga advance, Anda bisa langsung mengikuti SEO Fundamental Course Batch 6.
Materi akan dibawakan langsung oleh founder DailySEO ID, Ilman Akbar. Jadi, tunggu apa lagi? Segera daftarkan dirimu sekarang juga!



